

L’actualité IA du 30 avril 2025
📰 En Bref : Les actus IA de la semaine du 30 avril 2025
(Un petit coup d’œil rapide pour briller à la machine à café)
- Genie 2 : L’IA de DeepMind qui transforme une image en monde 3D jouable : Une avancée majeure dans la génération d’environnements virtuels interactifs.
-
Mistral Small 3.1 : Le modèle français qui fait de l’ombre aux géants : Un modèle open source performant, multimodal et multilingue.
-
Gemma 3 : L’IA open source de Google qui tient dans votre poche : Un modèle léger, performant et multilingue, optimisé pour fonctionner sur divers appareils.
- QwQ-32B : L’IA chinoise qui réfléchit plus vite que son ombre : Un modèle de raisonnement performant et accessible, développé par Alibaba.
-
Qwen3 d’Alibaba : L’IA chinoise qui rivalise avec les meilleurs : Des performances impressionnantes sur des configurations modestes.
-
Mistral OCR : L’outil qui lit vos documents comme jamais : Une solution OCR multimodale et multilingue, surpassant les leaders du marché.
- Gemini : Créez votre assistant IA personnalisé gratuitement : Google démocratise la personnalisation de son assistant IA avec les « Gems ».
-
GPT-4.1 : L’IA qui voit loin (très loin) : Une capacité de contexte étendue à un million de tokens, des performances accrues en codage et en suivi d’instructions, et une efficacité améliorée.
-
GPT-4.5 : L’IA d’OpenAI qui pense (presque) comme un humain : Une amélioration notable en compréhension contextuelle et en intelligence émotionnelle.
- OpenAI donne de la voix : des modèles audio qui écoutent et parlent comme des pros : Des améliorations majeures en transcription et synthèse vocale, avec des voix personnalisables.
- ChatGPT transforme vos photos en chefs-d’œuvre animés : Une nouvelle fonctionnalité permet de convertir vos images en styles Ghibli, Pixar et bien d’autres.
-
ChatGPT retourne le test de Turing : GPT-4.5 a été perçu comme plus humain que de véritables humains lors d’une étude récente.
- L’IA de Google révolutionne la recherche scientifique : Co-Scientist, l’IA de Google, a formulé en 48 heures une hypothèse que des chercheurs ont mis 10 ans à élaborer.
-
Gemini Robotics : Google donne des bras à son IA : L’intégration de l’IA dans la robotique pour des actions physiques.
Imaginez dessiner un petit robot dans une forêt et, en moins d’une minute, pouvoir explorer ce monde en 3D, sauter, nager et interagir avec des objets comme dans un jeu vidéo. C’est exactement ce que propose Genie 2, la dernière création de Google DeepMind.
Ce modèle d’IA, qualifié de foundation world model, est capable de générer une infinité d’environnements 3D interactifs à partir d’une simple image ou d’une description textuelle. Entraîné sur un vaste ensemble de vidéos, Genie 2 simule des interactions réalistes, des animations sophistiquées et des comportements dynamiques de personnages et d’objets.
Les applications potentielles sont vastes : du prototypage rapide de jeux vidéo à la formation d’agents d’IA dans des environnements variés. Toutefois, cette technologie soulève également des questions éthiques, notamment concernant les données utilisées pour l’entraînement du modèle et les implications en matière de propriété intellectuelle.
🇫🇷 Mistral Small 3.1 : Le modèle français qui fait de l'ombre aux géants
La startup française Mistral AI frappe fort avec la sortie de Mistral Small 3.1, un modèle de langage de 24 milliards de paramètres qui allie performance et accessibilité. Conçu pour fonctionner efficacement sur du matériel grand public (une seule carte RTX 4090 ou un Mac avec 32 Go de RAM), ce modèle open source sous licence Apache 2.0 se distingue par ses capacités multimodales, sa prise en charge multilingue et une fenêtre de contexte étendue à 128 000 tokens.
Parmi ses points forts :
-
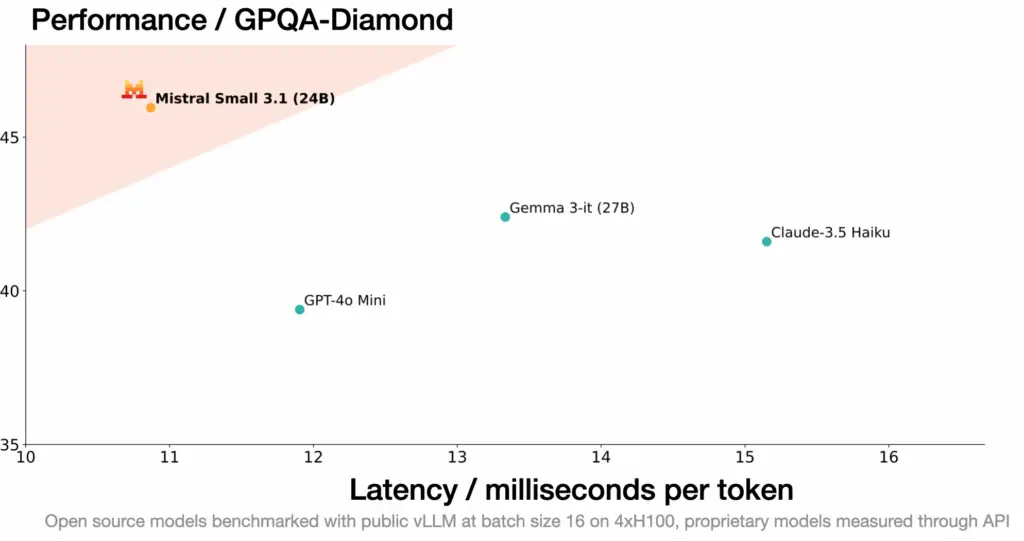
Performance : Il surpasse des modèles comme Gemma 3 et GPT-4o Mini dans plusieurs benchmarks, notamment en génération de texte, raisonnement et compréhension multimodale.
-
Vitesse : Capable de traiter jusqu’à 150 tokens par seconde, il offre une réactivité appréciable pour des applications en temps réel.
-
Polyvalence : Adapté à une variété d’applications, de l’assistance conversationnelle à la compréhension d’images, en passant par l’analyse de documents complexes.
Avec Mistral Small 3.1, Mistral AI confirme son ambition de proposer des alternatives européennes crédibles aux géants américains de l’IA, tout en promouvant une approche open source et accessible.
💎 Gemma 3 : L'IA open source de Google qui tient dans votre poche
Google dévoile Gemma 3, une famille de modèles d’IA open source conçus pour être légers, performants et accessibles. Disponibles en plusieurs tailles (1B, 4B, 12B et 27B), ces modèles sont optimisés pour fonctionner efficacement sur une variété d’appareils, des smartphones aux stations de travail, en passant par les ordinateurs portables.

Parmi les caractéristiques notables de Gemma 3 :
-
Multimodalité : Capacité à comprendre et à générer du texte, à analyser des images et des vidéos courtes, ouvrant la voie à des applications interactives et intelligentes.
-
Multilinguisme : Support natif pour plus de 35 langues et prise en charge pré-entraînée de plus de 140 langues, facilitant le développement d’applications globales.
-
Fenêtre de contexte étendue : Avec une capacité de 128 000 tokens, Gemma 3 peut traiter de longues séquences d’informations, améliorant ainsi la compréhension contextuelle.
-
Efficacité : Conçu pour fonctionner sur des configurations matérielles modestes, y compris une seule GPU ou TPU, rendant l’IA avancée plus accessible.
De plus, Google introduit ShieldGemma 2, un outil de sécurité intégré visant à filtrer les contenus explicites ou dangereux, renforçant ainsi l’engagement de l’entreprise envers une IA responsable.
Avec Gemma 3, Google continue de démocratiser l’accès à l’intelligence artificielle, offrant aux développeurs des outils puissants pour créer des applications innovantes et responsables.
🧠 QwQ-32B : L'IA chinoise qui réfléchit plus vite que son ombre
Sources : https://github.com/QwenLM/QwQ
Le géant chinois Alibaba a récemment dévoilé QwQ-32B, un modèle d’intelligence artificielle spécialisé dans le raisonnement complexe. Avec ses 32 milliards de paramètres, QwQ-32B rivalise avec des modèles de pointe tels que DeepSeek-R1, tout en étant plus économe en ressources.
Ce modèle se distingue par sa capacité à effectuer des raisonnements approfondis, notamment en mathématiques et en programmation, grâce à l’intégration de techniques d’apprentissage par renforcement. Il est également conçu pour être accessible, pouvant fonctionner sur des configurations matérielles modestes, ce qui le rend idéal pour les développeurs et chercheurs disposant de ressources limitées.
QwQ-32B est disponible en open source sous licence Apache 2.0, permettant ainsi à la communauté de l’explorer, de l’adapter et de l’améliorer. Cette initiative s’inscrit dans la volonté d’Alibaba de promouvoir une intelligence artificielle responsable et collaborative.
🐉 Qwen3 d'Alibaba : L'IA chinoise qui rivalise avec les meilleurs
Alibaba lance Qwen3, une série de modèles d’intelligence artificielle allant de 0,6 à 235 milliards de paramètres. Le modèle phare, Qwen3-235B-A22B, offre des performances comparables à celles de DeepSeek-R1 et des modèles d’OpenAI, tout en étant optimisé pour fonctionner comme un modèle de 22 milliards de paramètres. Avec une prise en charge de 119 langues et des capacités de raisonnement avancées, Qwen3 se positionne comme une alternative sérieuse aux modèles occidentaux.
Une fonctionnalité notable est le mode de pensée mixte, permettant de basculer entre un mode « réflexion » détaillé et un mode « rapide » pour des réponses succinctes. Cette flexibilité est particulièrement utile pour les tâches complexes nécessitant un raisonnement approfondi ou des réponses rapides.
De plus, Qwen3 est distribué sous licence Apache 2.0, offrant une utilisation commerciale sans frais de licence, ce qui le rend accessible aux développeurs et entreprises souhaitant intégrer une IA performante sans contraintes juridiques majeures.
📄 Mistral OCR : L'outil qui lit vos documents comme jamais
Sources : https://mistral.ai/fr/news/mistral-ocr
La startup française Mistral AI continue d’impressionner avec le lancement de Mistral OCR, une API d’OCR (reconnaissance optique de caractères) qui redéfinit les standards du domaine. Contrairement aux solutions traditionnelles, Mistral OCR ne se contente pas d’extraire du texte : elle comprend la structure des documents, y compris les images, les tableaux, les équations mathématiques et les mises en page complexes comme celles en LaTeX.

Ce qui distingue Mistral OCR :
-
Multimodalité : Capacité à traiter des documents contenant du texte, des images, des tableaux et des formules mathématiques, en préservant leur structure et leur mise en page.
-
Multilinguisme : Support natif pour des dizaines de langues, avec une précision de reconnaissance atteignant 99,02 %, surpassant ainsi des solutions comme Google Document AI et Azure OCR.
-
Performance : Traitement jusqu’à 2 000 pages par minute sur un seul nœud, idéal pour les entreprises ayant de gros volumes de documents à numériser.
-
Intégration facile : Résultats exportables en formats structurés tels que Markdown ou JSON, facilitant l’intégration dans des systèmes d’analyse ou des bases de données.
Disponible via la plateforme développeur de Mistral, la Plateforme, Mistral OCR est proposé à un tarif compétitif de 1 000 pages par dollar, avec une efficacité doublée en traitement par lots. Une version en libre essai est également accessible via leur interface conversationnelle Le Chat.
Avec Mistral OCR, Mistral AI confirme son ambition de proposer des outils d’intelligence artificielle performants, accessibles et adaptés aux besoins des entreprises modernes.
💎 Gemini : Créez votre assistant IA personnalisé gratuitement

Google franchit une nouvelle étape dans la personnalisation de l’intelligence artificielle en rendant accessible à tous les utilisateurs la création de « Gems », des assistants IA personnalisés. Jusqu’à présent réservée aux abonnés de Gemini Advanced, cette fonctionnalité est désormais disponible gratuitement sur les applications mobiles iOS et Android.
Les « Gems » fonctionnent comme des variantes de Gemini, chacune avec ses propres instructions et comportements. Il est possible de définir le ton (formel, décontracté, humoristique), la longueur des réponses, et même d’ajouter des fichiers de référence pour enrichir les connaissances à long terme de votre assistant. Cette flexibilité permet de créer des assistants réellement adaptés à vos besoins, que ce soit pour la rédaction, la programmation ou l’apprentissage.
Pour créer votre propre Gem, il suffit de se rendre sur le site web gemini.google.com, de cliquer sur « Gestionnaire de Gems », puis sur « Nouveau Gem ». Après avoir nommé votre Gem et rédigé ses instructions, vous pouvez le prévisualiser et l’enregistrer. Une fois créé, votre Gem est accessible depuis l’application mobile Gemini.
Pour faciliter la prise en main, Google propose cinq Gems prédéfinis :
-
Assistant au brainstorming : pour générer des idées créatives.
-
Guide de carrière : pour élaborer un plan de carrière structuré.
-
Partenaire de code : pour assister dans les tâches de programmation.
-
Coach d’apprentissage : pour accompagner dans l’apprentissage de nouvelles compétences.
-
Assistant d’écriture : pour améliorer la qualité rédactionnelle de vos textes.
Avec cette initiative, Google renforce sa position dans le domaine de l’IA personnalisée, offrant aux utilisateurs la possibilité de façonner des assistants virtuels qui répondent précisément à leurs besoins spécifiques.
🧠 GPT-4.1 d'OpenAI : L'IA qui voit loin (très loin)
Sources : https://openai.com/index/gpt-4-1/
OpenAI a récemment lancé GPT-4.1, une évolution majeure de ses modèles de langage, axée sur des améliorations significatives en codage, en suivi d’instructions et en compréhension de contextes étendus.
Parmi les principales avancées de GPT-4.1 :
-
Fenêtre de contexte étendue : GPT-4.1 peut traiter jusqu’à 1 million de tokens, contre 128 000 pour GPT-4o, permettant une meilleure gestion des longues conversations et des documents volumineux.
-
Améliorations en codage : Le modèle atteint 54,6 % sur le benchmark SWE-bench Verified, surpassant GPT-4o de 21,4 points et GPT-4.5 de 26,6 points, ce qui en fait un outil de choix pour les développeurs.
-
Suivi d’instructions optimisé : Sur le benchmark MultiChallenge de Scale, GPT-4.1 obtient 38,3 %, soit une amélioration de 10,5 points par rapport à GPT-4o, renforçant sa capacité à suivre des instructions complexes.
-
Efficacité accrue : GPT-4.1 est 40 % plus rapide et 26 % moins coûteux que GPT-4o, offrant des performances supérieures à un coût réduit.
Avec GPT-4.1, OpenAI continue de repousser les limites de l’intelligence artificielle, offrant des outils plus puissants, plus rapides et plus accessibles pour une variété d’applications, allant du développement logiciel à l’analyse de données complexes.
🧠 GPT-4.5 : L'IA d'OpenAI qui pense (presque) comme un humain
OpenAI a dévoilé GPT-4.5, surnommé « Orion », une version améliorée de ses modèles de langage, axée sur une compréhension contextuelle approfondie et une interaction plus naturelle.

Parmi les principales avancées de GPT-4.5 :
-
Compréhension contextuelle étendue : GPT-4.5 peut traiter des conversations plus longues et complexes, offrant des réponses plus cohérentes et pertinentes.
-
Intelligence émotionnelle accrue : Le modèle est capable de mieux saisir les nuances émotionnelles, rendant les interactions plus naturelles et empathiques.
-
Réduction des hallucinations : GPT-4.5 présente une diminution significative des réponses inexactes ou inventées, améliorant ainsi la fiabilité des informations fournies.
-
Multilinguisme renforcé : Le modèle excelle dans 15 langues, surpassant GPT-4o dans des benchmarks multilingues, notamment en français, allemand, japonais et arabe.
Cependant, GPT-4.5 est également plus gourmand en ressources, avec des coûts d’utilisation plus élevés que ses prédécesseurs. OpenAI prévoit de le retirer progressivement de son API d’ici juillet 2025, en faveur de modèles plus efficaces comme GPT-4.1.
Malgré cela, GPT-4.5 représente une étape importante vers des interactions homme-machine plus naturelles et intuitives, rapprochant un peu plus l’IA d’une compréhension humaine authentique.
🎤 OpenAI donne de la voix : des modèles audio qui écoutent et parlent comme des pros
OpenAI a récemment lancé une nouvelle génération de modèles audio, intégrés à son API, visant à améliorer les capacités de transcription (speech-to-text) et de synthèse vocale (text-to-speech). Ces modèles offrent une précision accrue, une meilleure reconnaissance des langues et une personnalisation vocale avancée.
📝 Transcription améliorée avec gpt-4o-transcribe et gpt-4o-mini-transcribe
Les nouveaux modèles de transcription surpassent les performances des modèles précédents, notamment Whisper, en réduisant le taux d’erreur de mots (Word Error Rate – WER) et en améliorant la reconnaissance des langues. Ils sont particulièrement efficaces dans des environnements complexes, tels que les accents variés, les bruits de fond et les vitesses de parole fluctuantes.
🗣️ Synthèse vocale expressive avec gpt-4o-mini-tts
Pour la première fois, les développeurs peuvent instruire le modèle de synthèse vocale non seulement sur le contenu à dire, mais aussi sur la manière de le dire. Par exemple, il est possible de demander au modèle de parler « comme un agent de service client empathique », ouvrant ainsi la voie à des applications plus personnalisées, allant du service client dynamique à la narration expressive pour des expériences de storytelling.
🧪 Innovations techniques
Ces avancées sont le fruit d’innovations ciblées en apprentissage par renforcement et d’un pré-entraînement approfondi avec des ensembles de données audio diversifiés et de haute qualité. Cette approche permet une meilleure compréhension des nuances de la parole et une performance exceptionnelle dans les tâches liées à l’audio.
🔧 Intégration simplifiée avec l’Agents SDK
OpenAI a également mis à jour son Agents SDK pour prendre en charge ces nouveaux modèles, facilitant ainsi la conversion de tout agent basé sur du texte en un agent vocal. Cette intégration simplifie le développement d’agents vocaux intelligents, offrant des interactions plus naturelles et intuitives avec les utilisateurs.
Avec ces nouveaux modèles audio, OpenAI renforce sa position dans le domaine de l’intelligence artificielle vocale, offrant aux développeurs des outils puissants pour créer des agents vocaux plus précis, expressifs et personnalisables.
🎨 ChatGPT transforme vos photos en chefs-d'œuvre animés

OpenAI a intégré une fonctionnalité de génération d’images directement dans son modèle GPT-4o. Cette nouveauté permet aux utilisateurs de transformer leurs photos en œuvres d’art dans des styles variés, notamment ceux des studios Ghibli, Pixar, ou encore Disney (et plus encore dans le lien ci-dessus). Il suffit de télécharger une photo sur ChatGPT et de demander, par exemple, « transforme cette image dans le style du Studio Ghibli » pour obtenir une version animée de votre cliché.
Cette fonctionnalité a rapidement gagné en popularité sur les réseaux sociaux, où de nombreux utilisateurs partagent leurs créations. Cependant, face à l’engouement massif, OpenAI a dû mettre en place des limites temporaires sur le nombre de générations d’images par jour pour les utilisateurs gratuits, afin de gérer la charge sur ses serveurs.
Il est important de noter que, bien que cette fonctionnalité permette de créer des images dans des styles artistiques reconnaissables, OpenAI a pris des mesures pour éviter la reproduction exacte du style d’artistes vivants, afin de respecter les droits d’auteur et les considérations éthiques.
Avec cette innovation, ChatGPT offre une nouvelle dimension créative à ses utilisateurs, leur permettant de réimaginer leurs souvenirs et portraits dans des univers artistiques enchanteurs.
🧠 ChatGPT retourne le test de Turing
Des chercheurs de l’université de Californie à San Diego ont récemment soumis plusieurs chatbots, dont GPT-4.5, à une version modernisée du test de Turing. Ce test, conçu pour évaluer si une machine peut imiter l’intelligence humaine au point d’être indiscernable d’un humain, a révélé des résultats surprenants.
Lors de l’étude, les participants ont interagi avec différents interlocuteurs, certains humains, d’autres étant des IA comme GPT-4.5, GPT-4o, LLaMa-3.1-405B et ELIZA. Fait remarquable, GPT-4.5 a été identifié comme humain dans 73 % des cas lorsqu’il était programmé pour se comporter comme tel, surpassant ainsi les véritables humains dans ces interactions.
Ce résultat souligne les avancées significatives dans le domaine de l’intelligence artificielle, où les modèles de langage deviennent de plus en plus sophistiqués, au point de tromper même des observateurs avertis. Cependant, il est important de noter que ce succès ne signifie pas que l’IA possède une conscience ou une intelligence équivalente à celle des humains, mais plutôt qu’elle est capable de simuler efficacement des comportements humains dans des contextes spécifiques.
Cette performance de GPT-4.5 relance le débat sur les implications éthiques et sociétales de l’IA, notamment en ce qui concerne la confiance, la transparence et l’utilisation responsable de ces technologies avancées.
🧬 L’IA de Google révolutionne la recherche scientifique
Des chercheurs de l’Imperial College London ont consacré dix années à étudier les mécanismes de résistance des superbactéries aux antibiotiques. Récemment, ils ont soumis leur problématique à Co-Scientist, une intelligence artificielle développée par Google et basée sur Gemini 2.0. En seulement 48 heures, l’IA a formulé la même hypothèse que celle que les chercheurs avaient mis une décennie à établir.
Le professeur José R. Penadés, impliqué dans l’étude, a exprimé sa stupéfaction face à cette performance, allant jusqu’à interroger Google sur une possible fuite de données, ce qui n’était évidemment pas le cas. Co-Scientist a non seulement confirmé leur hypothèse, mais a également proposé quatre autres pistes plausibles, dont une que l’équipe envisage désormais d’explorer.
Bien que l’IA ne puisse remplacer les validations expérimentales, son aptitude à analyser rapidement d’immenses volumes de données et à générer des hypothèses pertinentes pourrait considérablement accélérer le processus de recherche scientifique. Cette avancée souligne le potentiel transformateur de l’intelligence artificielle dans le domaine de la science.
🤖 Gemini Robotics : Google donne des bras à son IA
Google DeepMind a dévoilé Gemini Robotics, une nouvelle famille de modèles d’intelligence artificielle conçus pour doter les robots de capacités avancées en vision, langage et action. Basés sur le modèle Gemini 2.0, ces modèles permettent aux robots de comprendre des instructions complexes, de percevoir leur environnement et d’agir de manière autonome dans des situations variées.
Parmi les innovations majeures, on trouve Gemini Robotics-ER (Embodied Reasoning), qui offre aux robots une compréhension approfondie de l’espace et du temps, leur permettant de manipuler des objets avec précision et d’adapter leurs actions en temps réel.
Ces avancées ouvrent la voie à des applications pratiques, comme des robots capables de plier du linge, de préparer des repas ou d’assister les personnes âgées dans leurs tâches quotidiennes. Google envisage également l’intégration de ces modèles dans des robots humanoïdes, en collaboration avec des partenaires industriels.
Avec Gemini Robotics, Google franchit une étape significative vers la création de robots véritablement intelligents et utiles, capables d’interagir naturellement avec le monde physique et de s’adapter à des environnements en constante évolution.
💡 Des questions, des remarques, ou juste envie de papoter IA ? On ne mord pas (sauf les robots affamés). Rejoins-nous ici
