

Qu’est-ce qu’un modèle multimodal ?
🤖 Modèles multimodaux : l’IA qui voit, lit et écoute
Imagine un robot qui ne se contente pas de lire un texte, mais qui peut aussi reconnaître un chat sur une photo, comprendre une blague dans une vidéo, ou même répondre à une question à partir d’un schéma gribouillé sur un post-it. Ce n’est pas de la science-fiction : c’est ce qu’on appelle un modèle multimodal.






📚 D'abord, c’est quoi “modal” ?
Rien à voir avec le tissu ou le style vestimentaire. En intelligence artificielle, une modalité, c’est une forme de donnée :
Le texte (comme ce que tu lis)
L’image (comme ce mème de chat que tu as vu hier)
Le son (musique, voix, bruit de casserole)
La vidéo (qui combine image + son)
Pendant longtemps, les IA étaient un peu comme ces étudiants qui ne bossent qu’une seule matière : il y avait les IA qui lisaient, celles qui regardaient des images, d’autres qui écoutaient. Chacune restait dans sa zone de confort.
🧠 Et maintenant, bim : la multimodalité
Un modèle multimodal, c’est une IA qui sait jongler avec plusieurs de ces modalités en même temps. Par exemple, tu peux lui montrer une image d’un plat et lui demander : “Quelle est la recette ?”
Elle va regarder l’image, comprendre ce qu’elle voit, l’associer à des mots, puis te répondre. Comme un bon cuisinier… sauf qu’elle ne sent pas encore les odeurs (ouf).
🕹️ Comment ça marche dans les grandes lignes ?
👉 Le modèle est entraîné sur des montagnes de données combinant plusieurs types d’informations. Par exemple, des images avec des descriptions, des vidéos avec sous-titres, des dialogues avec gestuelles, etc.
👉 Il apprend à faire des liens entre ce qu’il voit, ce qu’il entend, et ce qu’il lit. Comme un bébé qui comprend que le mot “chien” correspond à cette boule de poils qui aboie dans le jardin.
👉 Ensuite, il peut générer du texte à partir d’une image, lire une question et y répondre en regardant une vidéo, ou même décrire un graphique.
🎮 Quelques exemples concrets
ChatGPT-4 avec vision (coucou 👋) peut regarder une image et répondre à des questions dessus. Tu peux lui montrer une capture d’écran de ton ordi en panique, et il t’aide à comprendre pourquoi ta vie numérique s’effondre.
Google Gemini, Claude, et d’autres font pareil : ils comprennent à la fois texte, image, son… et parfois, tout en même temps.
Des applis comme Be My Eyes aident les personnes malvoyantes en décrivant ce qu’elles montrent avec leur caméra.
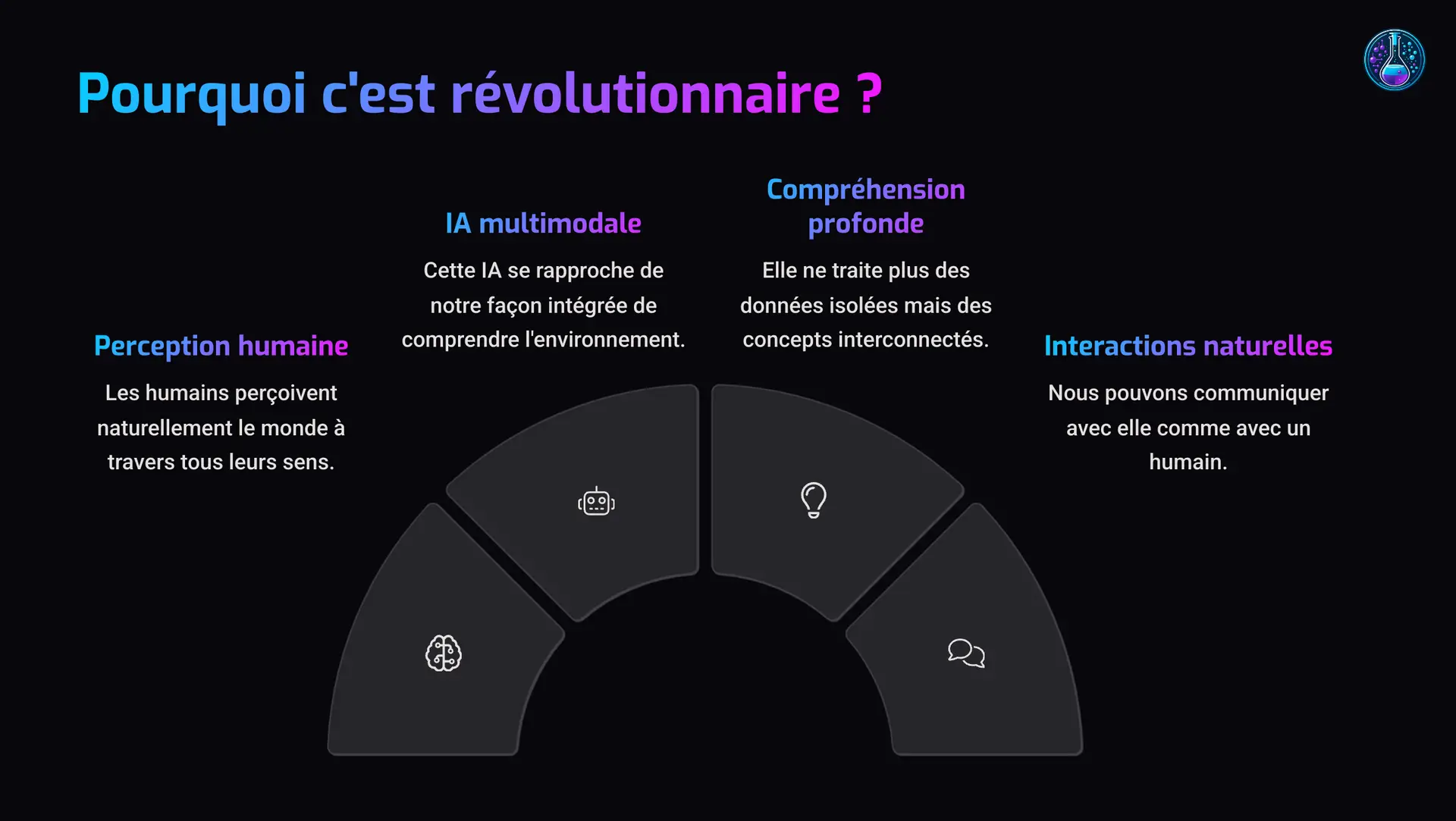
🤯 Pourquoi c’est révolutionnaire ?
Parce que ça rapproche l’IA de notre manière humaine de percevoir le monde. On ne vit pas que dans des textes ou que dans des sons. On combine tout ça naturellement. Les IA multimodales, c’est un pas de plus vers une intelligence qui comprend vraiment ce qu’on lui montre, et pas juste des mots en l’air.
🎤 Conclusion : l’IA qui voit, entend et comprend
Les modèles multimodaux sont en train de devenir les superstars de l’intelligence artificielle. Ils ne sont plus “mono-tâches” mais savent dialoguer avec le monde comme un humain (en version geek et sans caféine). Et le plus fou ? Ce n’est que le début…
💡 Des questions, des remarques, ou juste envie de papoter IA ? On ne mord pas (sauf les robots affamés). Rejoins-nous ici
